
Journal of Resources and Ecology >
Tourist Satisfaction with Panjin Red Beach Based on Online Comments
Received date: 2024-12-20
Accepted date: 2025-03-10
Online published: 2025-05-28
Supported by
Basic Research Project of Liaoning Provincial Department of Education(LJKMZ20221469)
Economic and Social Development Research Project of Liaoning Province(2024Lsbkt-104)
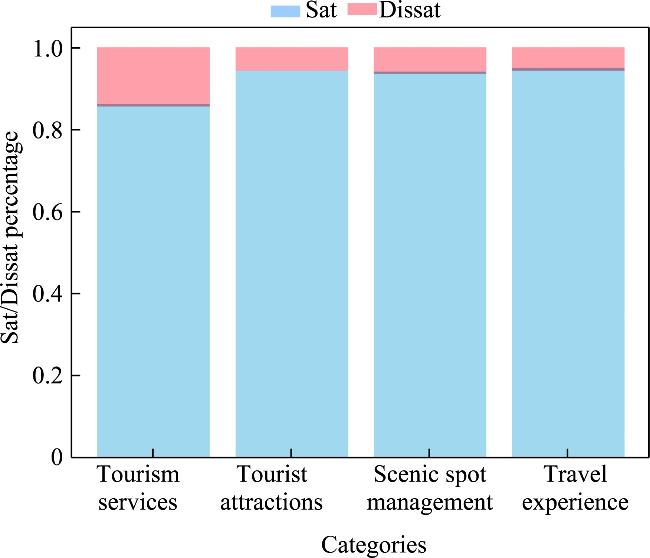
Tracking and investigating tourist satisfaction and accurately identifying the key factors that affect tourist satisfaction have always been among the top priorities for academia and tourist attraction operators. With the rise of online travel, analysis based on online comments has become an important method for tracking and surveying tourist satisfaction. This article examined the online comments of tourists for the Panjin Red Beach Scenic Corridor Scenic Area (hereinafter referred to as Red Beach) on Ctrip as an example. Using natural language processing to classify the tourist evaluations into topics, the main topics of concern were identified as tourism services, tourism attractions, scenic area management, and tourism experience. Through the 5-level rating of Ctrip’s online gaming customer satisfaction, an analysis was conducted on tourist satisfaction and the topics of greatest concern to the tourists were ranked. The results showed that the satisfaction levels from high to low are: tourism experience, tourism attractions, scenic area management, and tourism services. Therefore, satisfaction with related content under the service topic was the lowest so this aspect urgently needs to be improved and enhanced.
GAI Xuerui , LI Jiahui , HU Xinyao . Tourist Satisfaction with Panjin Red Beach Based on Online Comments[J]. Journal of Resources and Ecology, 2025 , 16(3) : 868 -874 . DOI: 10.5814/j.issn.1674-764x.2025.03.022
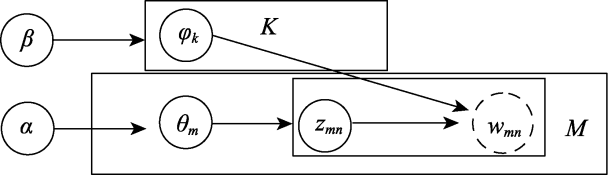
Figure 1 Block representation of LDA probabilistic graph modelNote: Nodes α and β are hyperparameters of the model, where node φk represents the word distribution parameter of the topic, node θm represents the topic distribution parameter of the text, node zmn represents the topic, and node wmn represents the word. K is the number of topics and M is the total number of online texts (the same notation is used below). |
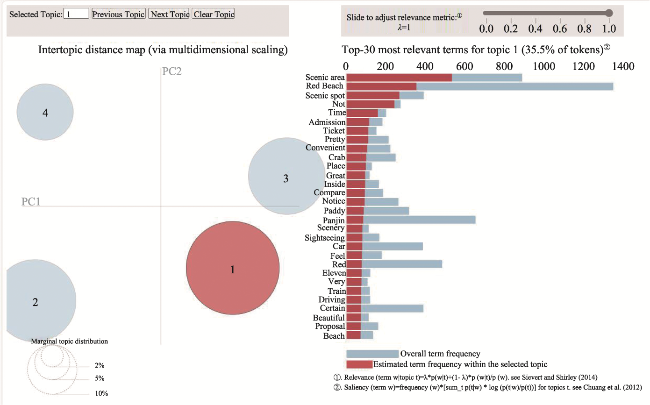
Figure 2 Visualization of topic clustering for online comments by Red Beach tourists using PyLDAvis |
Table 1 Topic classification and corresponding topic words for online comments from Red Beach tourists |
| Topic | Topic 1: Tourism services | Topic 2: Tourist attractions | Topic 3: Scenic spot management | Topic 4: Travel experience | ||||
|---|---|---|---|---|---|---|---|---|
| Topic words | Documented frequency value | Topic words | Documented frequency value | Topic words | Documented frequency value | Topic words | Documented frequency value | |
| 1 | Service | 0.060 | Red | 0.032 | Scenic spot | 0.085 | Recommend | 0.063 |
| 2 | Ticket | 0.022 | Crab | 0.031 | Red beach | 0.065 | Interesting | 0.051 |
| 3 | Train | 0.012 | Wetland | 0.030 | Management | 0.039 | Pretty good | 0.048 |
| 4 | Sightseeing car | 0.011 | Suaeda salsa | 0.026 | Wetland | 0.030 | Experience | 0.045 |
| 5 | Strengthen | 0.009 | Paddy | 0.019 | Environment | 0.023 | Okay | 0.034 |
| 6 | Attitude | 0.008 | Beach | 0.018 | Staff | 0.014 | Interesting | 0.027 |
| 7 | Self-driving tour | 0.007 | Food | 0.016 | Convenient | 0.012 | Spectacular | 0.022 |
| 8 | Guide | 0.006 | Reed marshes | 0.011 | Destruction | 0.005 | Cost performance | 0.018 |
| 9 | Improve | 0.005 | Water bird | 0.008 | Degradation | 0.001 | Favorable comment | 0.011 |
Figure 3 Satisfaction response chart of online topic classification for Red Beach tourist comments |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}