
Journal of Resources and Ecology >
Change of Agriculture Area over the Last 20 Years: A Case Study of Nainital District, Uttarakhand, India
|
Saurabh PARGAIEN, E-mail: saurabhpargaien@gmail.com |
Received date: 2022-12-08
Accepted date: 2023-02-25
Online published: 2023-08-02
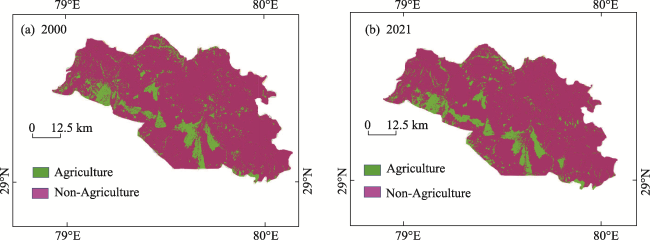
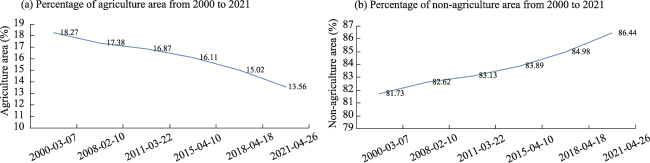
This study performs the time series analysis of agriculture land in the Nainital District of Uttarakhand, India. The study utilizes Landsat satellite images for the classification of agriculture and non-agriculture land over a time duration of 21 years (2000‒2021). Landsat 5, 7 and 8 satellites data have been used to classify the study area with Random Forest classifier. The Landsat satellite images are processed using the Google Earth Engine (GEE) platform. The selection of Random Forest classier has been based on a comparative analysis among Random Forest (RF), Support Vector Machines (SVM) and Classification and Regression Trees (CART). Overall accuracy, user accuracy and producer accuracy and Kappa coefficient has been evaluated to determine the best classifier for the study area. The overall accuracy for RF, SVM and CART for the year 2021 is 96.38%, 94.44% and 91.94% respectively. Similarly, the Kappa coefficient for RF, SVM and CART was 0.96, 0.89, 0.81 respectively. The classified images of Landsat in agriculture and non-agriculture area over a period of 21 years (2000-2021) shows a decrement of 4.71% in agriculture land which is quite significant. This study has also shown that the maximum decrease in agriculture area in last four years, i.e., from 2018 to 2021. This kind of study is very important for a developing country to access the change and take proper measure so that flora and fauna of the region can be maintained.
Key words: machine learning; land classification
Saurabh PARGAIEN , Rishi PRAKASH , Ved Prakash DUBEY . Change of Agriculture Area over the Last 20 Years: A Case Study of Nainital District, Uttarakhand, India[J]. Journal of Resources and Ecology, 2023 , 14(5) : 983 -990 . DOI: 10.5814/j.issn.1674-764x.2023.05.009
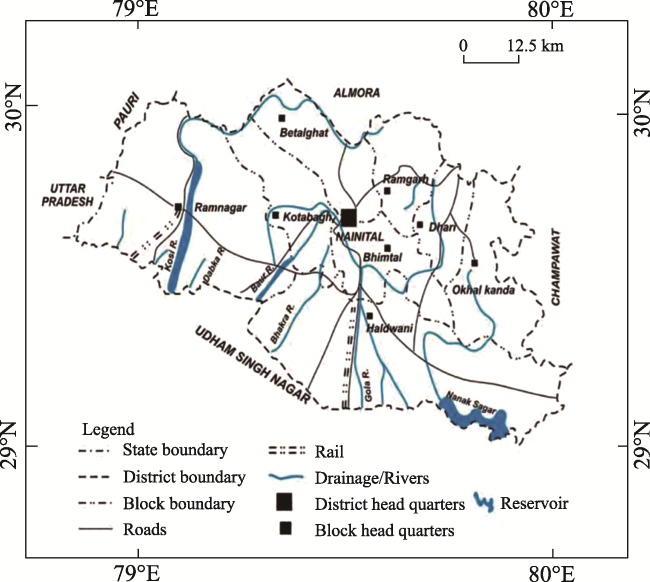
Fig. 1 Location map of Nainital District in the state of Uttarakhand, India |
Table 1 Details of landsat data used in the study |
| S.N. | Acquisition date | Sensor | Spatial resolution | Cloud cover |
|---|---|---|---|---|
| 1 | 2021-04-26 | Landsat 8 | 30 m | Less than 10% |
| 2 | 2020-03-22 | Landsat 8 | 30 m | Less than 10% |
| 3 | 2019-05-07 | Landsat 8 | 30 m | Less than 10% |
| 4 | 2018-04-18 | Landsat 8 | 30 m | Less than 10% |
| 5 | 2017-02-10 | Landsat 8 | 30 m | Less than 10% |
| 6 | 2016-05-14 | Landsat 8 | 30 m | Less than 10% |
| 7 | 2015-04-10 | Landsat 8 | 30 m | Less than 10% |
| 8 | 2014-01-10 | Landsat 8 | 30 m | Less than 10% |
| 9 | 2013-03-13 | Landsat 7 | 30 m | Less than 10% |
| 10 | 2012-01-20 | Landsat 7 | 30 m | Less than 10% |
| 11 | 2011-03-22 | Landsat 7 | 30 m | Less than 10% |
| 12 | 2010-03-19 | Landsat 7 | 30 m | Less than 10% |
| 13 | 2009-03-16 | Landsat 7 | 30 m | Less than 10% |
| 14 | 2008-02-10 | Landsat 7 | 30 m | Less than 10% |
| 15 | 2007-05-14 | Landsat 7 | 30 m | Less than 10% |
| 16 | 2006-02-04 | Landsat 7 | 30 m | Less than 10% |
| 17 | 2005-04-06 | Landsat 7 | 30 m | Less than 10% |
| 18 | 2004-02-15 | Landsat 7 | 30 m | Less than 10% |
| 19 | 2003-02-12 | Landsat 7 | 30 m | Less than 10% |
| 20 | 2002-01-01 | Landsat 7 | 30 m | Less than 10% |
| 21 | 2001-01-21 | Landsat 5 | 30 m | Less than 10% |
| 22 | 2000-03-07 | Landsat 5 | 30 m | Less than 10% |
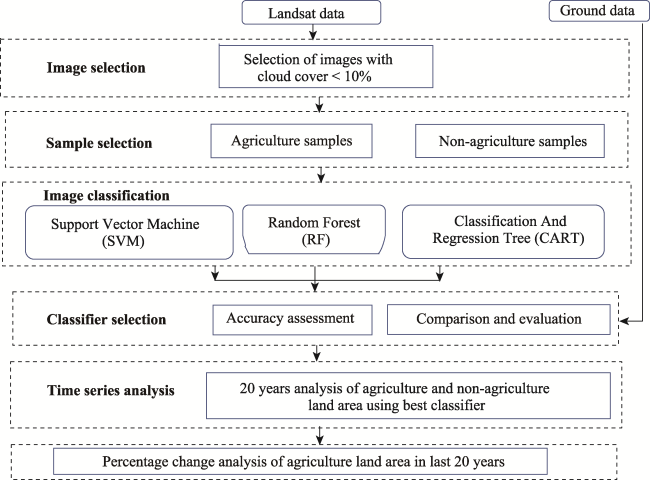
Fig. 2 The methodology used for LULC classification |
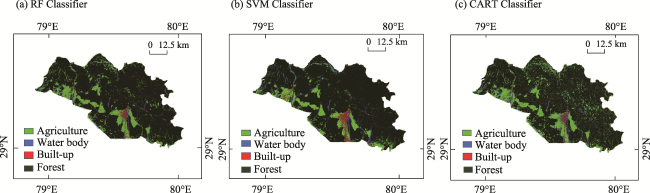
Fig. 3 Classified outputs of Nainital District of 26 April 2021 based on different classifier |
Table 2 Confusion matrix for the LULC map of 26 April 2021 using (a) RF Classifier; (b) SVM Classifier and (c) CART Classifier |
| Classes | (a) RF Classifier | (b) SVM Classifier | (c) CART Classifier | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Water body | Forest | Built-up | Agriculture | UA (%) | Water body | Forest | Built-up | Agriculture | UA (%) | Water body | Forest | Built-up | Agriculture | UA (%) | |
| Water body | 54 | 2 | 1 | 3 | 90.00 | 59 | 0 | 1 | 0 | 98.33 | 53 | 0 | 3 | 4 | 88.33 |
| Forest | 0 | 59 | 0 | 1 | 98.33 | 0 | 54 | 0 | 6 | 90.00 | 1 | 52 | 0 | 7 | 86.67 |
| Built-up | 5 | 0 | 85 | 0 | 94.44 | 4 | 0 | 86 | 0 | 95.56 | 7 | 0 | 83 | 0 | 92.22 |
| Agriculture | 0 | 1 | 0 | 149 | 99.33 | 1 | 2 | 6 | 141 | 94.00 | 4 | 1 | 2 | 143 | 95.33 |
| PA (%) | 91.53 | 95.16 | 98.84 | 97.39 | 92.19 | 96.43 | 92.47 | 95.92 | 81.54 | 98.11 | 94.32 | 92.86 | |||
| OA (%) | 96.38 | 94.44 | 91.94 | ||||||||||||
| Kappa coefficient | 0.96 | 0.89 | 0.81 | ||||||||||||
Note: UA: The user accuracy; PA: Producer accuracy; OA: Overall accuracy. |
Fig. 4 Agriculture and non-agriculture land area classification using random forest classifier (a) year 2000 (b) year 2021 |
Fig. 5 Percentage of land area using RF classifier analysis from 2000 to 2021 (a) agriculture area (b) non-agriculture area |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
Directorate of Census Operations in Uttarakhand. 2022. Nainital District: Population 2011-2022 data. https://www.census2011.co.in/census/district/584-nainital.Html. Viewed on 2022-09-20.
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
Global Forest Watch. 2021. https://www.globalforestwatch.org/dashboards/country/IND. Viewed on 2021-10-20.
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}