
Journal of Resources and Ecology >
Research on Forest Phenology Prediction based on LSTM and GRU Model
|
GUAN Peng, E-mail: guanpeng@bjfu.edu.cn |
Received date: 2021-07-15
Accepted date: 2022-01-20
Online published: 2023-01-31
Supported by
The Fundamental Research Funds for the Central Universities(2021ZY74)
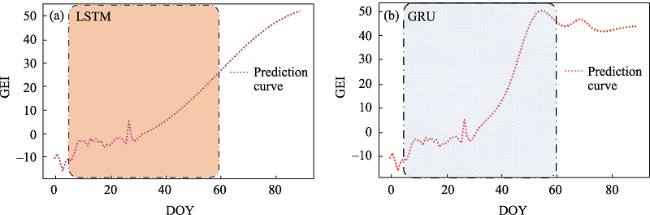
Research on forest phenology is an important parameter related to climate and environmental changes. An optical camera was used as a near-earth remote sensing satellite device to obtain forest images, and the data of Green excess index (GEI) in the images were calculated, which was fitted with the seasonal variation curve of GEI data by double Logistic method and normalization method. LSTM and GRU deep learning models were introduced to train and test the GEI data. Moreover, the rationality and performance evaluation of the deep learning model were verified, and finally the model predicted the trend of GEI data in the next 60 days. Results showed: In the aspects of forest phenology training and prediction, GRU and LSTM models were verified by histograms and autocorrelation graphs, indicating that the distribution of predicted data was consistent with the trend of real data, LSTM and GRU model data were feasible and the model was stable. The differences of MSE, RMSE, MAE and MAPE between LSTM model and GRU model were 0.0014, 0.013, 0.008 and 5.26%, respectively. GRU had higher performance than LSTM. The prediction of LSTM and GRU models about GEI data for the next 60 days both showed a trend chart consistent with the change trend of GEI data in the first half of the year. GRU and LSTM were used to predict GEI data by deep learning model, and the response of LSTM and GRU deep learning models in forest phenology prediction was realized, and the performance of GRU was better than that of LSTM model. It could further reveal the growth and climate change of forest phenology in the future, and provide a theoretical basis for the application of forest phenology prediction.
Key words: forest phenology; GEI; LSTM model; GRU model; prediction
GUAN Peng , ZHENG Yili . Research on Forest Phenology Prediction based on LSTM and GRU Model[J]. Journal of Resources and Ecology, 2023 , 14(1) : 25 -34 . DOI: 10.5814/j.issn.1674-764x.2023.01.003
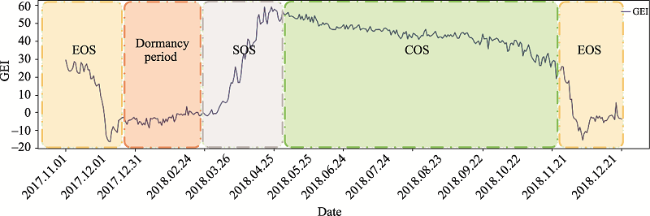
Fig.1 Region of interest in different season |
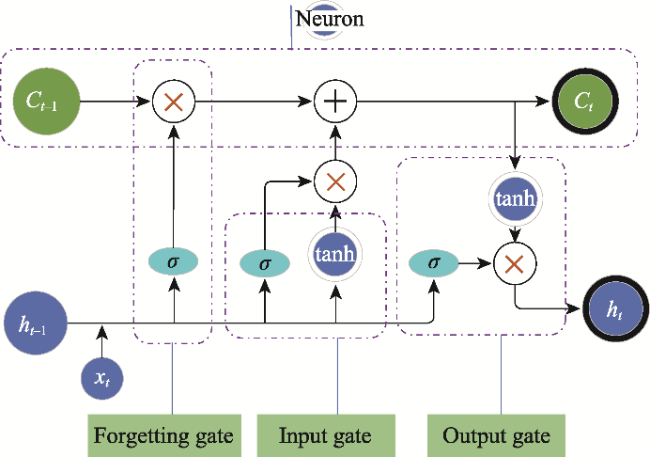
Fig.2 LSTM neural network structure |
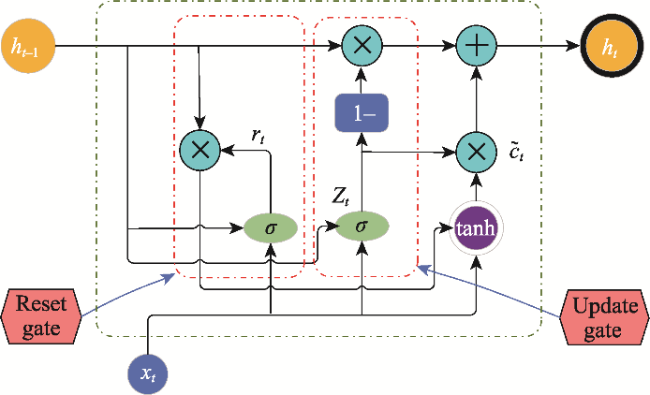
Fig. 3 GRU neural network structure |
Fig. 4 Growing status |
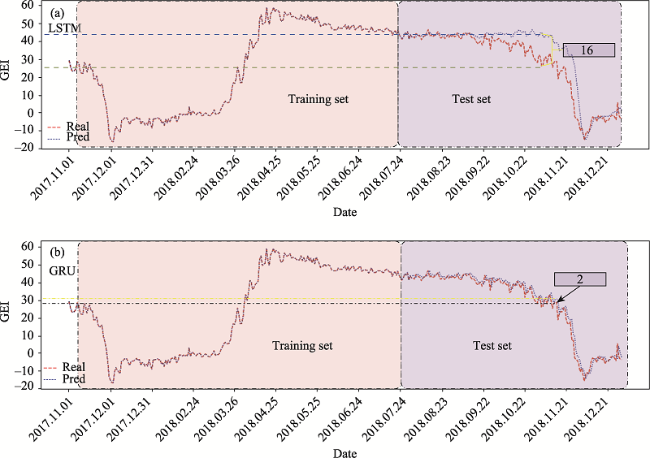
Fig. 5 Test results of (a) LSTM model and (b) GRU modelNote: The values 16 and 2 in the frame in the figure represent the difference between the true value and the predicted value. |
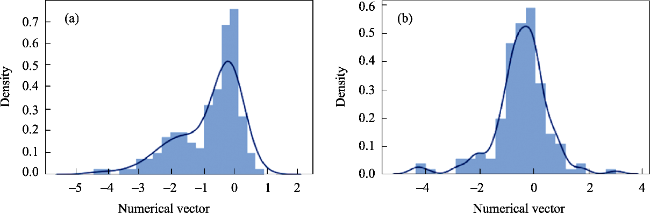
Fig. 6 Data distribution graph based on (a) LSTM model and (b) GRU model |
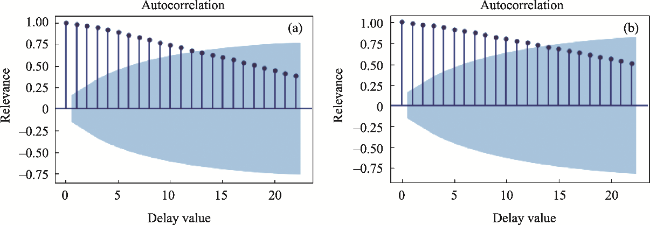
Fig. 7 Autocorrelation graph of (a) LSTM model and (b) GRU model |
Table 1 Performance evaluation |
| Moudle | Inspection criteria | |||
|---|---|---|---|---|
| MSE | RMSE | MAE | MAPE (%) | |
| LSTM | 0.003 | 0.054 | 0.041 | 17.81 |
| GRU | 0.0016 | 0.041 | 0.033 | 12.55 |
Fig. 8 Model prediction results of (a) LSTM model and (b) GRU modelNote: The orange region is the prediction curve of LSTM; The blue area is the prediction curve of the GRU. |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}